Data engineering and architecture are essential for building and managing data systems that can handle the increasing complexity and scale of data in the modern world. However, designing and evaluating data engineering and architecture is not a trivial task, as it involves many trade-offs and challenges. To help with this process, this page presents a table of some architecture and engineering principles that can be used as guidelines or criteria for data engineering and architecture. These principles are based on some web sources that we have cited, but they are not definitive or comprehensive. They are meant to provide some inspiration and direction for your own data projects.
The lack of standardized data ingestion platfor framwork leading to ad-hoc, inefficient processes for acquiring, validating, and transforming new data sources. This results in duplicative effort across teams, limited ability to scale data pipelines, and data quality issues.
The data ingestion framework will define a set of architectural principles, design criteria, maturity models and governance guides for data integration capabilities. It will cover cloud service guidelines, infrastructure provisioning, metadata repositories, ingestion workflow orchestration, data processing pipelines, storage environments and self-service design patterns. The principles and criteria aim to optimize quality, reuse, interoperability, monitoring and automation capabilities.
The framework delivers a structured methodology for evaluating and improving existing ingestion capabilities against industry wide best practices. This spans across multiple domains including integration patterns, data governance maturity, metadata completeness, pipeline efficiency metrics and technology standardization models.
© Nilay Parikh. All rights reserved. No warranty or liability implied.
For each area, measurable design criteria are defined aligned to progressive target states. Additional self-assessment models quantify infrastructure as code adoption, testing coverage, and workflow automation levels.
The principles guide optimal use of cloud-native services while allowing integration with existing systems. Collectively the dimensions and guiding metrics provide a comprehensive, transparent benchmark for architectural enhancements ultimately making onboarding more cost efficient and lower risk. The principles-driven approach allows the specifics of implementation to meet the unique needs of each organization.
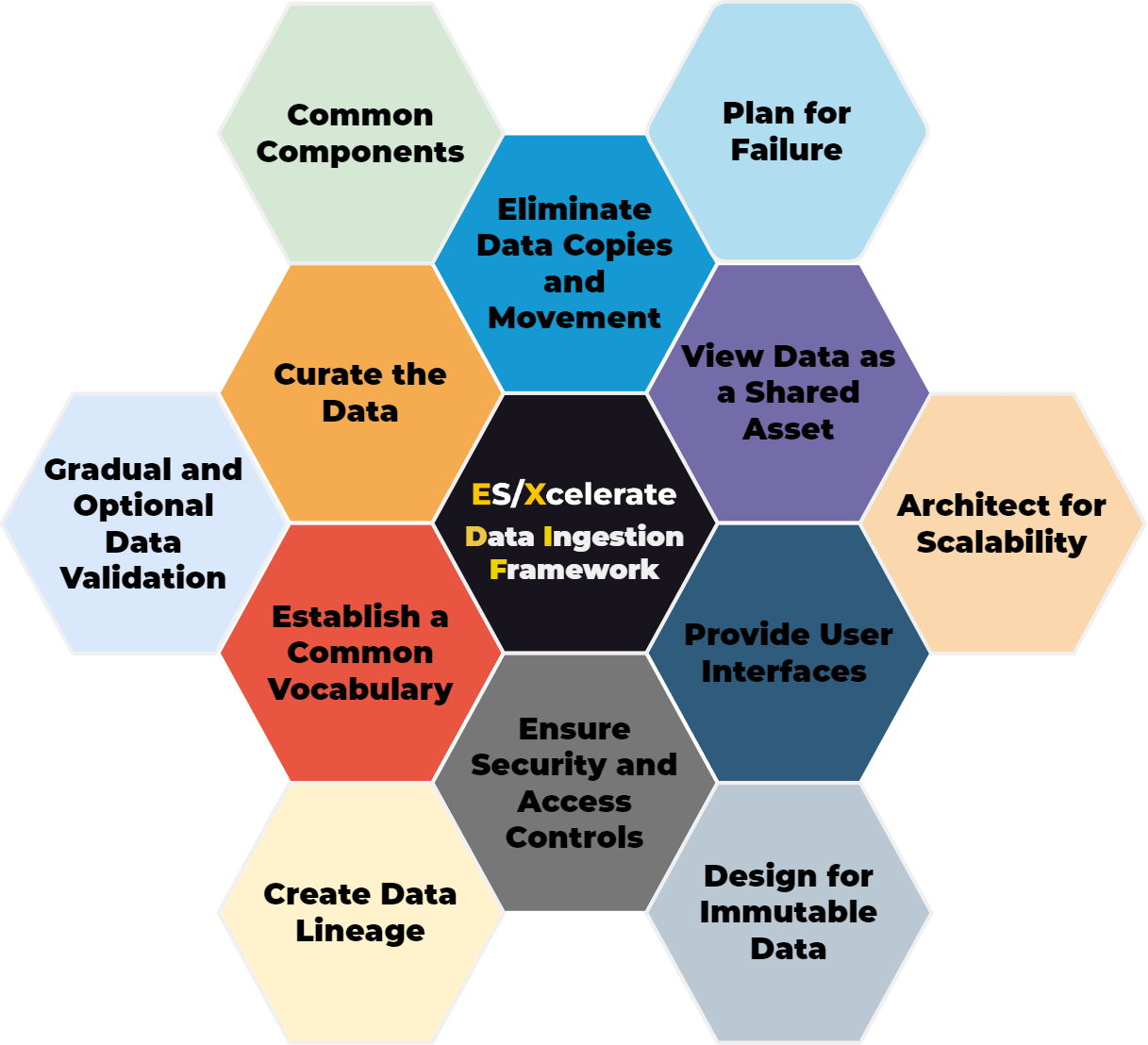
| Principle | Description |
|---|---|
| View data as a shared asset | Data should be accessible and reusable across different teams and applications, without compromising quality or security. |
| Provide user interfaces for consuming data | Data should be presented in a way that is easy to understand and analyze, using tools such as dashboards, reports, or visualizations. |
| Ensure security and access controls | Data should be protected from unauthorized access or modification, using methods such as encryption, authentication, authorization, and auditing. |
| Establish a common vocabulary | Data should be defined and documented using consistent terms and standards, to avoid confusion and ambiguity. |
| Curate the data | Data should be cleaned, validated, enriched, and transformed to meet the needs and expectations of the consumers. |
| Eliminate data copies and movement | Data should be stored and processed in a way that minimizes duplication and transfer, to reduce costs and latency. |
| Choose common components wisely | Data should be built and deployed using modular and interoperable components, to enable flexibility and scalability. |
| Plan for failure | Data should be designed and tested to handle errors and exceptions, using techniques such as backup, recovery, and fault tolerance. |
| Architect for scalability | Data should be able to handle increasing volumes and varieties of data, using methods such as parallelism, distribution, and streaming. |
| Design for immutable data | Data should be treated as append-only and never overwritten or deleted, to preserve history and enable reproducibility. |
| Create data lineage | Data should be tracked and traced from source to destination, to provide visibility and accountability. |
| Gradual and optional data validation | Data should be validated at different stages and levels, depending on the use case and requirements. |

Executive layer, providing succinct architectural insights through graphical representations and value-driven roadmaps. Align organizational data strategies with business goals, offering transparent views of budgetary, risk, and capability trade-offs.

Design layer for comprehensive architectural principles, design patterns, and technical recommendations. Tailored for architects and engineers, it guides through modern best practices, balancing quality, cost, and agility for robust implementations.

Data governance teams find their compass in the Controls layer, offering predefined audit controls, risk indicators, and capability maturity blueprints. Quantify operational metrics, ensuring a rigorous approach to quality, compliance, and usage across data processes.
License
This work (ES/Xcelerate Framework) by Nilay Parikh is licensed under CC BY 4.0 or view a human-readable summary.
If the above licenses do not suit your needs, please contact us at [email protected] to discuss your terms. We also offer more flexible commercial license that do not require attribution. The different licensing approaches reflect the intellectual property and commercial considerations associated with various framework elements while still promoting access.
Disclaimer
The views expressed on this site are personal opinions only and have no affiliation. See full disclaimer, terms & conditions, and privacy policy. No obligations assumed.